开始学习分布式。
在这个练习中,我们将会使用 Go 实现一个叫作MapReduce的编程模型。
前言
在开始阅读本文之前,笔者希望你已经看过Google的论文MapReduce,本文只是对其的一个简单实现。当然,如果你的英文不是很好,也可以参照国内的一些翻译,感谢他们作出的贡献!
此外,mit的6.824课程也借用了这个模型作为lab1,一些其他的资源(代码和测试命令)在mit6.824上。
本文只是对整体的设计和思考做了些简述,代码由于课程的缘故不方便公开在GitHub上,以关键代码的形式放在文章中。
简述
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。其设计初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理,类似计算机中常见的分治思想。
首先假设有大量数据,我们希望统计数据当中每个单词出现的次数,结果保存在一个文件中。一个常见的思路是:首先将所有数据中的单词分割——即Map操作,然后排序并统计出现次数——即Reduce操作。但显然的问题是:
1.处理效率低下,一台计算机要进行大量数据的运算。
2.内存不足,需要读入大量数据分割,常见的排序难以满足要求。
因此,MapReduce应运而生。在这个模型下,有许多worker执行Map或Reduce操作,有一个Master负责调配整个系统的工作。具体流程如下图所示:
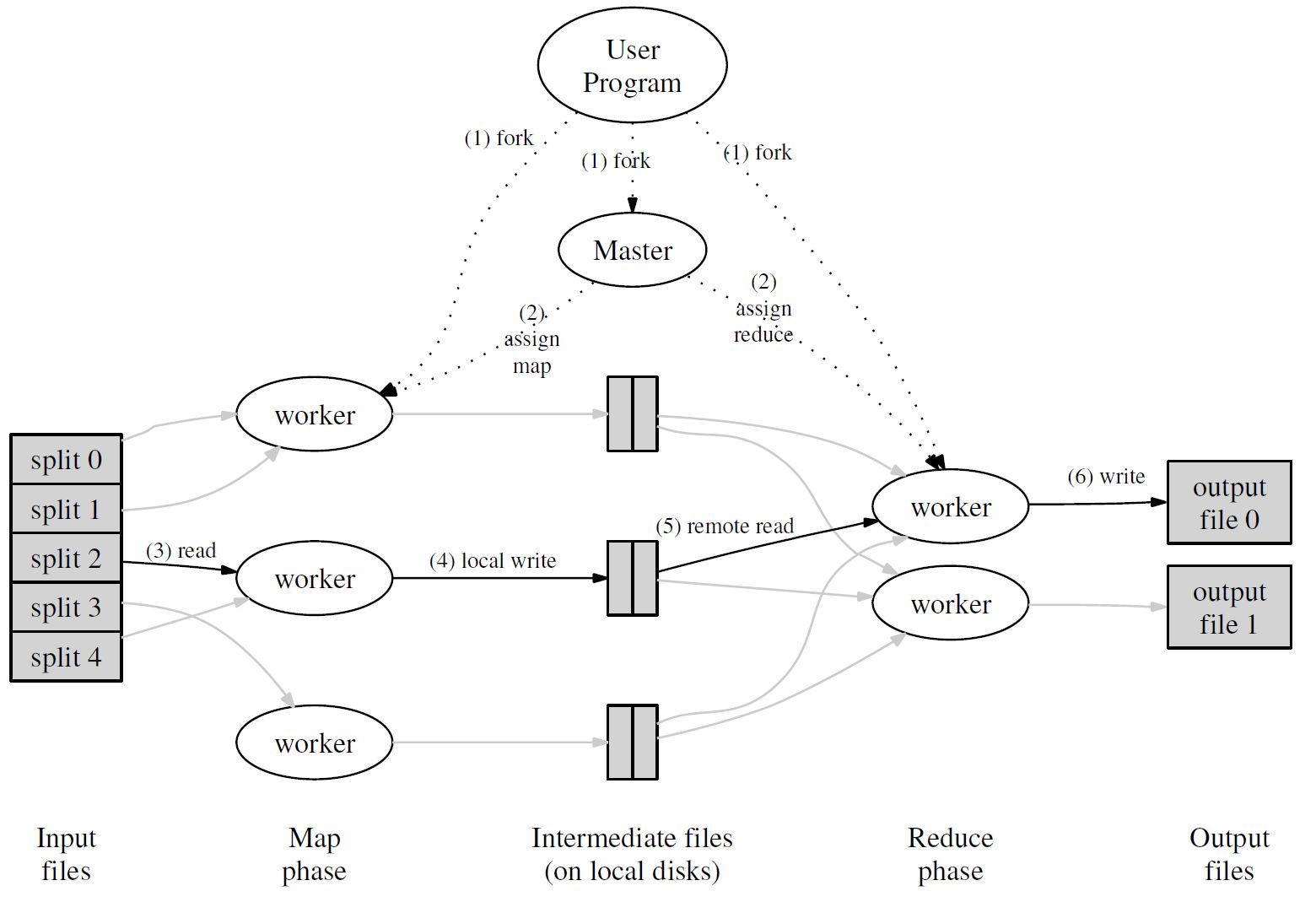
通过将Map调用的输入数据自动分割为M个数据片段的集合,Map调用被分布到多台机器上执行(其中每个集合中的数据以key-value形式保存,在这个案例下value通常为1,表示单词出现一次)。输入的数据片段能够在不同的机器上并行处理。使用分区函数将Map调用产生的中间key值分成R个不同分区(例如,hash(key) mod R),Reduce调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指定。最终生成结果文件。
2
reduce (k2,list(v2)) ->list(v2)
论文的具体内容在此不作赘述,接下来详述代码实现。
代码实现
Map和Reduce的具体操作代码在lab1中已经给出,我们只需要完成mr文件夹下的master.go、worker.go和rpc.go代码。
一.master.go
1.需要的变量类型
首先需要对整个系统的流程分阶段,其中Wait指Map任务都已下发但未全部提交成功。
1 | const MapPhase, ReducePhase, Wait, Finish = 0, 1, 2, 3 |
其次是会用到的结构体,采用Master作为整个系统的调配对象,MapTask表示每个Map任务,ReduceTask表示每个Reduce任务。
1 | type Master struct { |
我们采用通道的数据结构(队列也可以)来传递下发任务,同时对系统进行一定的加锁处理。
2.关键的方法
主要为发送任务和报告完成的方法,均由worker主动调用。
发送任务
1 | func (m *Master) SendTask(args *RPCArgs, reply *RPCReply) error { |
由于在lab1的第四个crash测试中,每个worker可能会出现异常退出或超时处理(事实上现实情况下分布式也很容易出现这种分区错误)。为保证这种分区容错性,我们对每个申请任务的worker都开启一个协程用以监视该任务是否完成(等待十秒),如果十秒过后还显示该任务未完成,master会将对应的任务重新加入到任务通道中。
报告完成
1 | func (m *Master) ReportTask(args *RPCArgs, reply *RPCReply) error { |
这里有两个值得注意的地方:
①为保障上文所述的分区容错性,我们采取了相应的措施。但随之带来一个问题:假设上一个worker并没有崩溃,只是速度过慢呢?当超时的任务被重新加入通道,而上一次的任务结果发回master。最终就会有两份相同的任务结果传回master。笔者采取的应对措施是只保留最先到达的。
②在lab1的第三个reduce parallelism测试中,需要保证各worker对于reduce的处理是并行的。但情况并非如此:因为我们采用的是通道。
一个比较清晰的例子是:假设我们现在有很多台worker,有一台因老化而运行速度过慢(事实上只要速度不完全一致就会出现这种情况)。很容易出现这样的场景:很多worker提交了MapTask,直到剩余一个任务未完成。此时MapTask通道为空,所有进入的worker都会阻塞在Map通道处。而唯一的老化worker在任务结束后会面临两个结果:要么执行完任务后提交,系统切换到reduce phase,而其他worker持续阻塞;要么执行任务失败,MapTask会被并发的协程重新放回到MapTask通道中,随机一个worker获得任务,而后重复上述过程,此时老化的worker依旧被阻塞。
然而,此时带来的唯一结果是:只有单一worker执行reduce任务。这是我们不希望看到的。
这也是前文所述Wait阶段的用处所在。将Map阶段严格分成任务全部下发——任务全部完成两个阶段,对于任务全部下发的情况,worker不会阻塞在Map通道处,而是等待一段时间,重新申请任务。
二.worker.go
1.Map处理流程
1 | //given mapf func & rpcreply, return the slice of intermediate data |
读入Map任务对应数据->整理成kv形式数组->将数组的所有内容以key即单词字符串为基准映射到相应区块->以json的形式保存为中间文件。由于相同的字符串会映射到同一个文件,因此无需担心计数错误的情况发生。
2.Reduce处理流程
1 | func ReduceProcess(reducef func(string, []string) string, task *RPCReply) (string, bool) { |
读入Reduce任务处理文件->排序->统计个数->输出为最终结果。如果排序时内存不足可以采用外部排序的方式。
测试结果

附录:mr包下代码全文
master.go
1 | package mr |
worker.go
1 | package mr |
rpc.go
1 | package mr |