最近用go写web时,在网上简单查了下客户端请求的代码,发现有的在读取response后会执行response.Body.Close(),有的则不会。在网上查阅了下发现如果不执行可能会导致goroutine泄漏。本着质疑到底的精神,笔者今天就做个实验验证一下,并对相关源码作一下深入的解析
受篇幅和冗余细节的限制,笔者将着重聚焦于整个流程和函数功能的阐释,而不会过分关注无关代码
验证
先来简单做个小验证
不执行response.Body.Close()
1 | package main |
执行response.Body.Close()
1 | package main |
在程序运行一段时间后,对对应进程执行top指令查看内存情况时,会发现如下结果:

可以发现如果不执行response.Body.Close(),整个进程所消耗的内存资源是会不断增加的
流程分析
引入
让我们从最开始讲起……
1 | func main() { |
http的get/post等请求最终会调用client.go下的func (c *Client) do(req *Request) (retres *Response, reterr error)这个方法。client就是请求的客户端,一般是采用默认的DefaultClient来作为方法的接收者进行调用
1 | func (c *Client) do(req *Request) (retres *Response, reterr error) { |
可以看到,关键的代码实际上就在c.send(req, deadline)这一行,那我们继续进入这个方法中
1 | func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeout func() bool, err error) { |
接着进入send(req, c.transport(), deadline)方法中
1 | func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) { |
在进入rt.RoundTrip(req)方法前,我们要先看一下这个方法的接收者——Transport
Transport
transport实现了RoundTripper接口,该接口只有一个方法RoundTrip(),故transport的入口函数就是RoundTrip()。transport的主要功能其实就是缓存了长连接,用于大量http请求场景下的连接复用,减少发送请求时TCP(TLS)连接建立的时间损耗,同时transport还能对连接做一些限制,如连接超时时间,每个host的最大连接数等
1 | type Transport struct { |
Transport.roundTrip
接下来就是重点了
rt.RoundTrip(req)这个方法的主要目的是:
- 参数校验: scheme, host, method, protocol…
- 获取缓存的或新建的连接
- 从获取的连接中取得response
1 | func (t *Transport) roundTrip(req *Request) (*Response, error) { |
这个方法的核心在两个地方,一个是通过t.getConn(treq, cm)获得可用的persistConn连接;另一个是调用pconn.roundTrip(treq)方法获取到response。让我们相继解释一下两个方法
Transport.getConn
这个方法分成以下几个步骤:
- 调用
t.queueForIdleConn获取一个空闲且可复用的连接,如果获取成功则直接返回该连接- 如果未获取到空闲连接则调用
t.queueForDial开始新建一个连接- 等待w.ready关闭,则可以返回新的连接
1 | func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) { |
这个方法又会导向以下两个函数:
Transport.queueForIdleConn
(*Transport).queueForIdleConn方法会根据请求的connectMethodKey从t.idleConn获取一个[]*persistConn切片, 并从切片中,根据算法获取一个有效的空闲连接。如果未获取到空闲连接,则将wantConn结构体变量(即形参w)放入t.idleConnWait[w.key]等待队列
Transport.queueForDial
这个方法比较复杂,主要涵盖获得一个新的连接及将其放入连接池的逻辑。因为很多地方与本文内容关系不大,暂且略过一些无关紧要之处,以后有机会再详谈。让我们把目光集中到它最终导向的一个很重要的方法——Transport.dialConn上
Transport.dialConn
这个方法的主要逻辑如下:
- 调用
t.dial(ctx, "tcp", cm.addr())创建TCP连接- 如果是https的请求, 则对请求建立安全的tls传输通道
- 为persistConn创建读写buffer, 如果用户没有自定义读写buffer的大小, 根据writeBufferSize和readBufferSize方法可知, 读写bufffer的大小默认为4096
- 执行
go pconn.readLoop()和go pconn.writeLoop()开启读写循环然后返回连接
1 | func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) { |
接下来就到了本文最关键的两个方法:读写循环了。但是先等一等,别忘了还有另一条线的逻辑我们搁置了好久,让我们把两条线合在一起
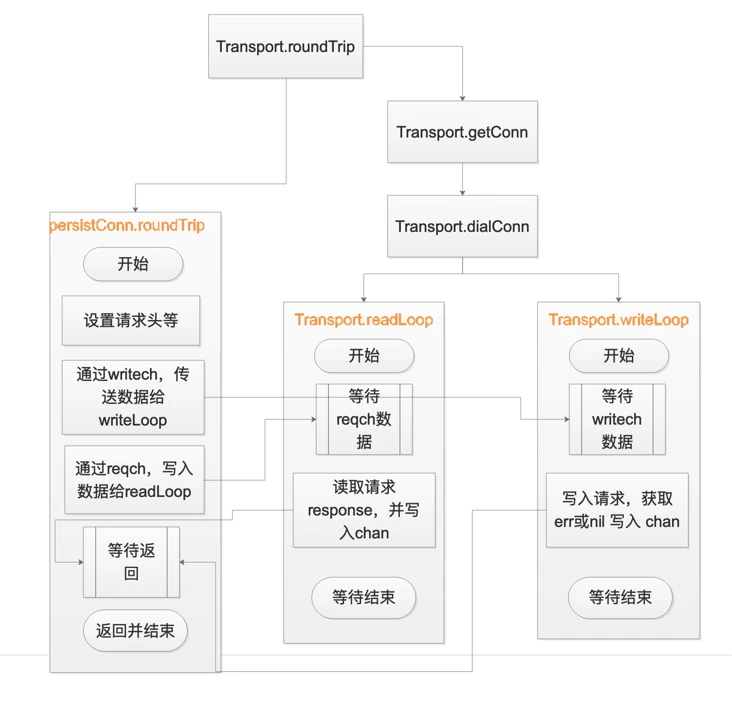
persistConn.roundTrip
persistConn是一个具体的连接实例,包括连接的上下文。而它的persistConn.roundTrip方法的目的其实就是获取到response并返回给上层,步骤如下:
- 向连接的writech写入writeRequest:
pc.writech <- writeRequest{req, writeErrCh, continueCh}, 参考(*Transport).dialConn可知pc.writech是一个缓冲大小为1的管道,所以会立即写入成功。writech由写循环读- 向连接的reqch写入
requestAndChan:pc.reqch <- requestAndChan, pc.reqch和pc.writech一样都是缓冲大小为1的管道。reqch用于获取客户端的请求信息并等待返回的response,由读循环读- 开启for循环select, 等待响应或者超时等信息
归根结底,这个函数的目的其实也就是创建个writeLoop 用到的chan,然后把request通过这个chan传给 persistConn.writeLoop ,然后再创建一个readLoop用到的chan,从这个chan中获取 persistConn.readLoop 获取到的 response,最后把response返回给上层函数
1 | func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) { |
persistConn.readLoop&persistConn.writeLoop
终于到了引起内存泄漏的两个函数了,先看简单的写循环:
1 | func (pc *persistConn) writeLoop() { |
其实就是把用户的请求写入连接的写缓存buffer,最后再flush
接下来是读循环
1 | func (pc *persistConn) readLoop() { |
解析到这里,大家应该也发现关键所在了:由于readLoop和writeLoop两个goroutine在写入请求并获取response返回后,并没有跳出for循环,而是继续阻塞在下一次for循环的select语句里面,所以,两个函数所在的goroutine并没有运行结束,自然也就导致了goroutine的泄露
为什么response.Body.Close()可以结束阻塞
其实close的主要逻辑就是通过调用 readLoop 定义的earlyCloseFn 方法,向waitForBodyRead的chan写入false,进而让readLoop退出阻塞,继而终止readLoop的goroutine。而readLoop在退出的时候,会关闭closech chan,进而让 writeLoop退出阻塞,终止writeLoop的goroutine
总结
由于底层的读写循环会一直阻塞,直到我们对Body进行Close或者把当前http请求的body读完。所以如果不对response.Body进行close,goroutine就会一直阻塞在原先的位置,连接也不能复用。感兴趣再研究一下代码会发现:
- 有Body没有读完,就执行Close的话,连接会被关闭,不会复用
- 如果读完了所有Body,可以不调用Close,连接也会被复用
所以最佳实践是:http请求发出后,如果没有错误,马上声明defer res.Body.Close(),避免资源泄露,然后尽量读完Body,好让连接复用
最后依旧用一张图来描述下整个流程: