之前写了个go的web框架,采用的路由树类似Trie树,将路由用”/“切分成字符串数组的形式,去逐一匹配每层对应的路径。而go的著名开源框架Gin采用的则是的Radix树。今天通过路由的实际应用,简单介绍下两种树并分析下优劣
Trie树
在实际路由应用中(如go的原生http库),很多时候我们会用到键值对的查找。通过一个键值key,去拿到它对应的值对象,也即路由函数。但是这里存在一些问题。首先,当存储的键值对很多的时候,很多多余的key值会浪费大量空间;其次,对于路由的具体应用,键值对的形式只能进行静态路由匹配,而Trie树更接近具体的每一条路径,能够实现动态路由、分组路由
下面用一张结构图展示一下Trie树:
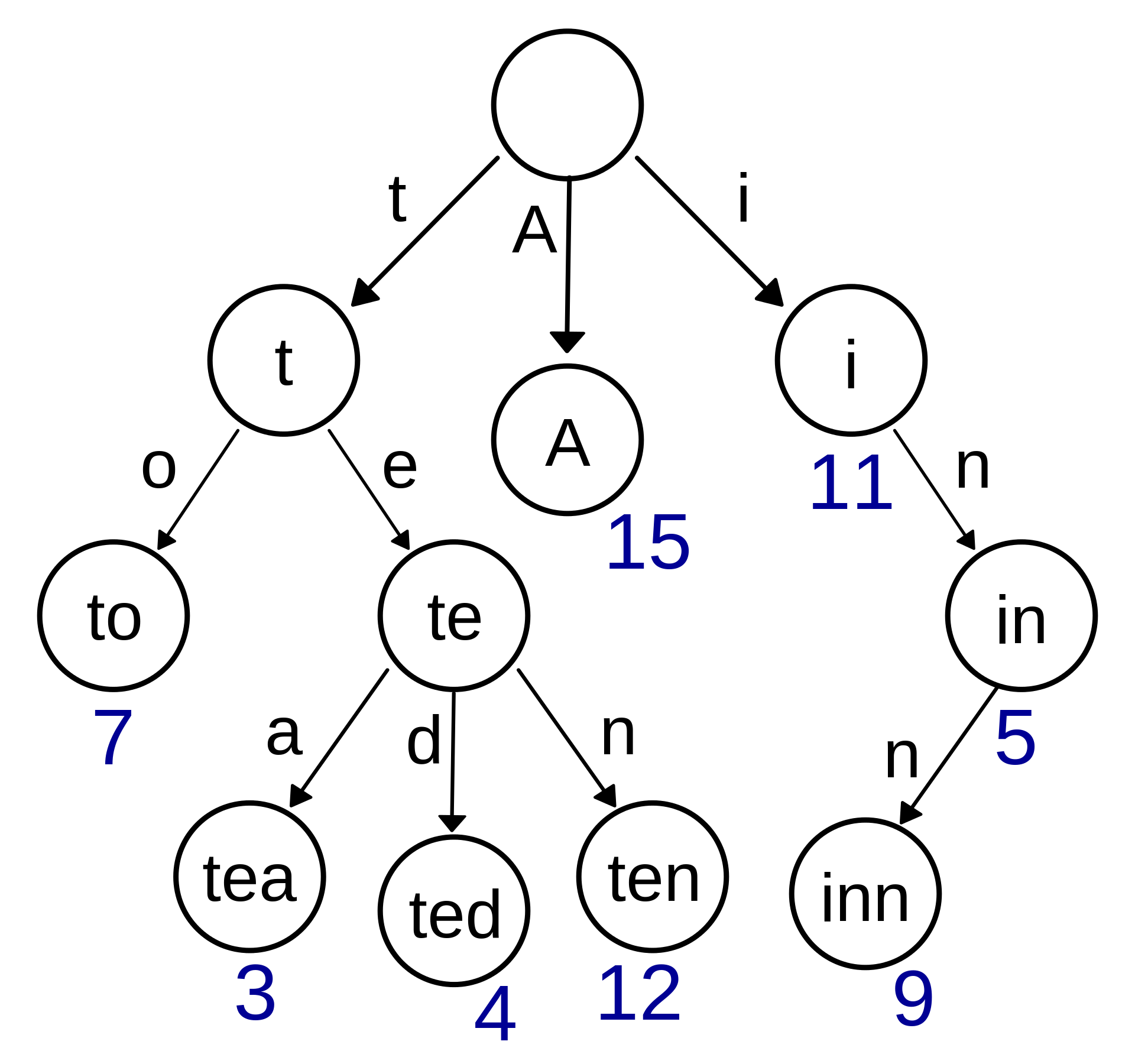
由图可知,对于空间来讲,所有其中的节点,其公共前缀被共享了,避免了大量的重复存储;对于时间来讲,对于某一key值的查询效率由它的长度k决定,从根节点依次向下,总共需要判断k次下一步的走向。
但是这个数据结构随之带来一个问题:如果它的key对应的节点构造的深度过深,它所消耗的时间也将会线性增长,效率大大降低。而一个衍生版本的Radix树使得原先这棵树构造得更“紧凑”了些
Radix树
Radix树,即基数树,也称压缩前缀树,是一种提供key-value存储查找的数据结构。与Trie不同的是,它对Trie树进行了空间优化,只有一个子节点的中间节点将被压缩。同样的,Radix树的插入、查询、删除操作的时间复杂度都为O(k)
我们还是用一张图展示一下:
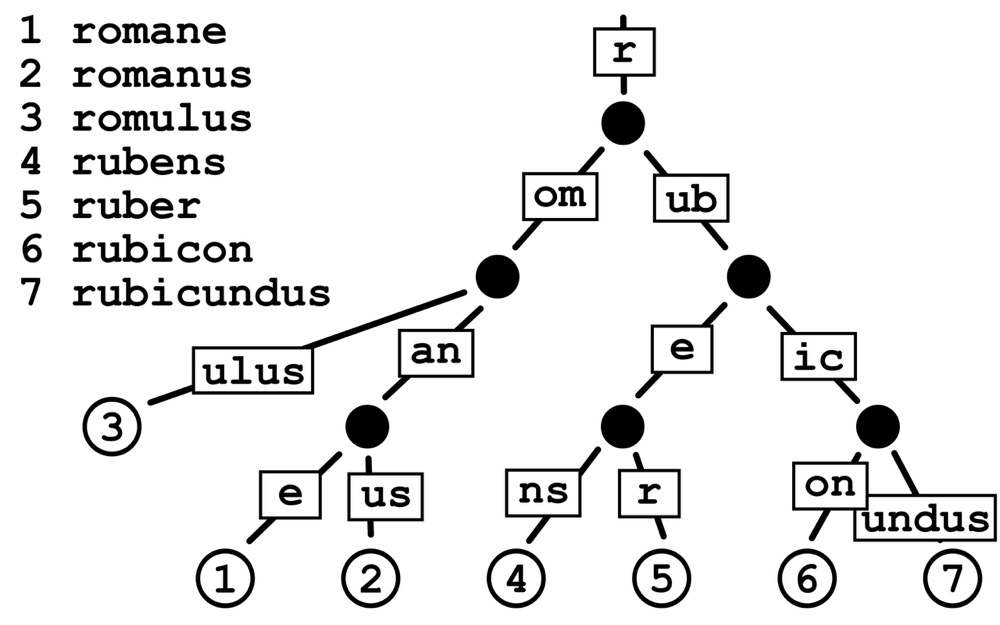
其实原理上也很好理解,就是将一条路径的子树叠加成一个节点,每次查询不需要逐层比较,有效降低了深度。同时他的插入和删除规则也和Trie树有所不同:
- 对于节点插入,当有新的key插入时,需要将原有的公共前缀分支拆分
- 对于节点删除,当删除一个现有key后,如果其父节点只有另外一个子节点key,则此子节点可以和父节点合并为一个新的节点
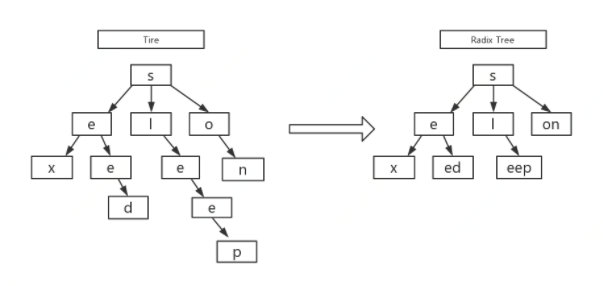
在web框架中的应用
一个路由树的简单实现
在路由当中可以用Trie树的思想实现,只不过每一层不是增加一个字符,而是按照”/“来分割
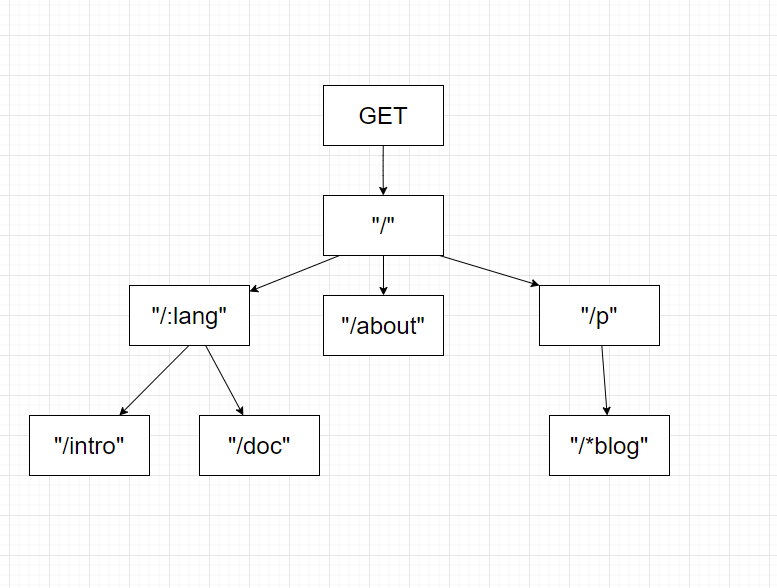
但是这样其实显得很笨拙:我需要遍历每层所有的节点去比较每层对应的path是否等于我请求的path。Gin在这里用Radix树的思想将其明显优化了
Radix树在Gin中的应用
Gin的路由本质上就是一颗Radix树,是由httprouter这个包实现的,举个例子简单说明一下:
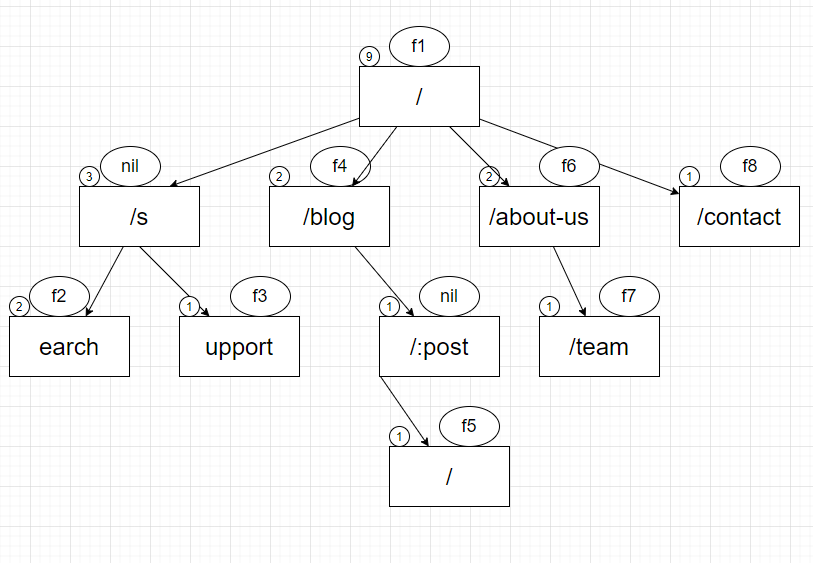
上图中,每个节点左上角表示路由的优先级,上方表示路由对应的响应函数(没有则为nil)。对应生成的代码如下所示:
1 | r.GET("/", f1) |
它将”search”和”support”进行了拆分,先经过”s”,再向下匹配,提升了效率
源码查看
1 | type node struct { |
具体的路由增加和匹配的源码受篇幅限制且与文章关系不大,作者就不赘述了
Gin中Radix树的局限性
Gin的路由局限性主要表现为路由冲突。比如,在已经注册了/blog/:post这条路由的情况下,将无法继续注册/blog/hot与/blog/a/b/c这两类路由。因为/blog/:post这条规则会把/blog/后面的元素当做:post变量来看待,因此当在/blog/后面追加其他路由时,均会与:post这个变量的路由冲突
所以,在一开始的路由设计时尽量遵循RESTFUL的风格,保证一定的规范,就能避免路由冲突
总结
本文简单分析了Trie树和Radix树的实现,以及在Gin中的相关应用和局限性。Gin通过Radix树的思想实现了动态路由、简化了路由匹配,同时带来了可能导致路由冲突的缺陷。因此,相关技术人员在设计路由时要尽量遵从一定规范